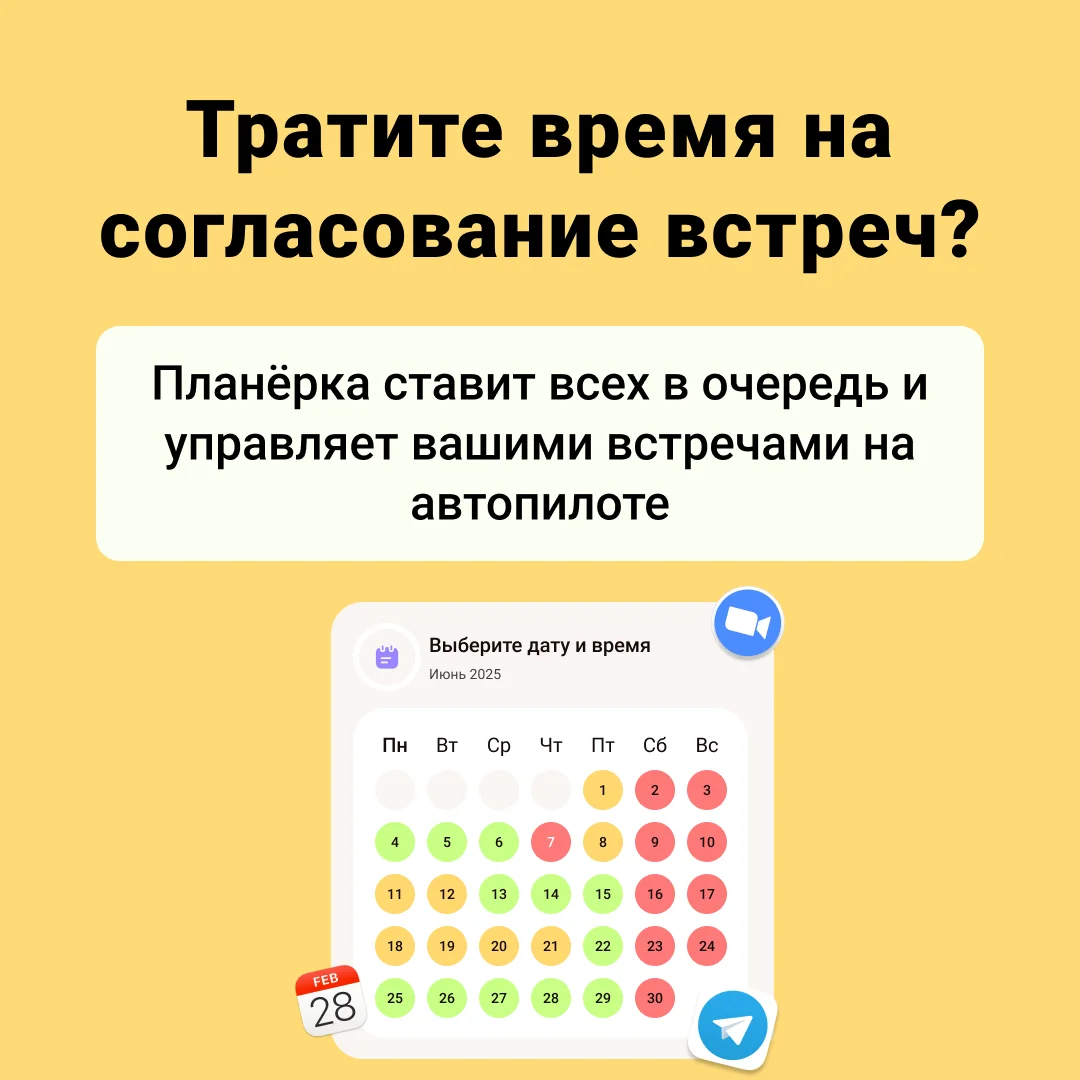
Помню, как в прошлом году на вечеринке друг шепнул: "Смотри, что ИИ сотворил с лицом той певицы в видео!" Мы все уставились в экран, и это было так убедительно, что на миг поверили в реальность. Но нет – чистый дипфейк порно, сгенерированный нейронными сетями. Я тогда нырнул в тему, экспериментируя с GAN-сетями, и осознал: технологии глубокого обучения превратили создание порно дипфейков сделать в игру для всех. От простых смен лиц в видео манипуляции до синтетического контента с знаменитостями – все доступно онлайн. В этом обзоре я ранжирую 15 инструментов, включая дипфейк порно бесплатно и премиум варианты для make deepfake porn.

Мы разберем качество изображения, реалистичные эффекты, видео редактирование и NSFW материалы. Плюс, коснемся этических вопросов, конфиденциальности данных и юридических аспектов, потому что за крутыми AI инструментами скрываются риски вроде неконсенсусного контента. Если вы ищете, как создать порно фейк или просто смотреть дипфейк порно видео, этот гид поможет, но помните: используйте responsibly.
Краткий обзор ТОП-15 deepfake для порно
- Обработчик фото Playbox: Фокус на фото для фейк порно, с быстрым AI.
- ВидеоДекоратор Gratz AI: Видео для porno deepfakes, с аудио синхронизацией.
- Porn Works AI: Для nudity в дип фейки порно.
- Видео редактор Нейро БумБум: Монтаж для секс дипфейк.
- Обработка фото: Простой для порно дипфейки.
- Обработка видео Gratz: Удаление одежды в deepfake порно.
- Бот Нейро БумБум: Генерация для сделать порно дип фейк.
- Генератор видео Stable Nude: Быстрое для фейки порно звезд.
- Turbotext: Промпты для deep fake porn.
- Promptchan: Для дипфейк порно знаменитости.
- Mylovely: Романтика в порно фейки знаменитости.
- Seduced: Седуктивные для фейк порно знаменитости.
- Aiallure: Аллюр для deepfakes porn.
- CFake: Архив для дипфейк порно русское.
- AdultDeepFakes: Видео для дипфейк ххх.
ТОП-15 face swap порно в деталях: от новичков до профи
1. Обработчик фото Playbox
⭐️ Средняя оценка: 4.2/5
➡️ Попробуй дипфейк порно бесплатно прямо сейчас

Этот инструмент специализируется на обработке фото для создания реалистичных фейковых изображений, используя машинное обучение для смены лиц в порнографическом контенте. Он идеален для тех, кто хочет быстро сгенерировать порно знаменитостей фейки без сложных настроек.
- Преимущества: Быстрая скорость обработки; поддержка высокого разрешения; интуитивный пользовательский интерфейс; бесплатный триал для тестов; интеграция с мобильными приложениями.
- Недостатки: Ограничения на размер файлов в бесплатной версии; иногда артефакты в мимике; требует хороших исходных материалов; нет видео поддержки; возможны водяные знаки.
- Кому подходит: Новичкам, ищущим простой способ для xxx deepfake или porno deep fake без глубоких знаний в ИИ.
✴ ✴ ✴
2. ВидеоДекоратор Gratz AI
⭐️ Средняя оценка: 4.5/5
➡️ Создай дип фейки порно с видео эффектами

Фокусируется на видео декорации, позволяя добавлять deepfake элементы в существующие клипы, с акцентом на синхронизацию аудио и реалистичные позы тела для секс дипфейк.
- Преимущества: Отличная lip sync; поддержка 4K; кастомизация опций; GPU ускорение для скорости; сообщество с туториалами.
- Недостатки: Высокие hardware требования; премиум для полного доступа; риски конфиденциальности; не всегда идеальная мимика; ограниченные датасеты. Кому подходит: Тем, кто хочет сделать порно дип фейк с динамикой, как в deepfake 18 сценариях.
✴ ✴ ✴
3. Porn Works AI
⭐️ Средняя оценка: 4.0/5
➡️ Генерируй фейки порно звезд молниеносно
Специализирован на бикини и nudity детекции, используя алгоритмы ИИ для создания дипфейк порно знаменитости с фокусом на голые знаменитости порно фейки.
- Преимущества: Быстрый онлайн доступ; реалистичные эффекты; премиум функции для кастомизации; поддержка русских знаменитостей; удобный экспорт.
- Недостатки: Ограничения в бесплатной версии; возможные этические вопросы; зависимость от качества фото; нет 3D моделирования; иногда низкая частота кадров.
- Кому подходит: Фанатам celebrity deepfake porn, ищущим быстрые порно фейки знаменитости.
✴ ✴ ✴
4. Видео редактор Нейро БумБум
⭐️ Средняя оценка: 4.3/5
➡️ Редактируй create deepfake porn легко

Универсальный редактор для видео, интегрирующий deep fake порно с монтажом, подходящий для порно фейки видео.
- Преимущества: Полная синхронизация; форматы экспорта; пользовательские рейтинги; обновления софта; интеграция с PyTorch.
- Недостатки: Сложный для новичков; подписка модели; риски безопасности; ограниченные бесплатные опции; нужда в датасетах.
- Кому подходит: Профи в дип фейк порно видео, желающим порно дипфейк онлайн.
✴ ✴ ✴
5. Обработка фото
⭐️ Средняя оценка: 4.1/5
➡️ Смотри дипфейк порно смотреть в фото

Простой обработчик для фото, фокусирующийся на fake porn celebrity с эмоциональными эффектами.
- Преимущества: Легкий интерфейс; бесплатный доступ; высокое качество; мобильная версия; гайды для новичков.
- Недостатки: Нет видео; артефакты; конфиденциальность; ограничения размера; базовые функции.
- Кому подходит: Тем, кто начинает с дипфейк порно русские знаменитости.
✴ ✴ ✴
6. Обработка видео Gratz
⭐️ Средняя оценка: 4.4/5
➡️ Удаляй одежду в дипфейк порно знаменитостей
Инструмент для удаления одежды, идеальный для порно фейки на знаменитостей с AI.
- Преимущества: Реалистичные nudity; скорость; кастомизация; поддержка celeb deepfake; облачные сервисы.
- Недостатки: Этические риски; премиум для best; утечки данных; не для видео; юридические аспекты.
- Кому подходит: Для deepfake porn maker в NSFW.
✴ ✴ ✴
7. Бот Нейро БумБум
⭐️ Средняя оценка: 4.6/5
➡️ Работай с porno deepfakes профессионально

Генератор для порно deepfakes, с 3D и анимацией.
- Преимущества: Высокое разрешение; инновации; партнерства; отзывы; альтернативы.
- Недостатки: Дорогой; сложный; вред от злоупотреблений; регуляции; обнаружение фейков.
- Кому подходит: Экспертам в голые знаменитости порно фейки.
✴ ✴ ✴
8. Генератор видео Stable Nude
⭐️ Средняя оценка: 4.2/5

Быстрое раздевание для make deepfake porn.
- Преимущества: Простота; deepfake бесплатно; фейк секс опции; онлайн; скорость.
- Недостатки: Качество варьируется; риски; ограничения; нет аудио; базовый.
- Кому подходит: Новичкам в дип фейк онлайн.
✴ ✴ ✴
9. Turbotext
⭐️ Средняя оценка: 4.0/5
➡️ Пиши промпты для deepfake video porn
Текстовый для порно фейки российских знаменитостей.
- Преимущества: Легкие промпты; интеграция; бесплатный; удобство; кастом.
- Недостатки: Нет визуала; зависимость; ошибки; премиум; этика.
- Кому подходит: Для порно фейки на звезд.
✴ ✴ ✴
10. Promptchan
⭐️ Средняя оценка: 4.3/5
➡️ Начни промпты для porno deep face
AI для порно видео fake.
- Преимущества: Мобильный; качество; обновления; сообщество; экспорт.
- Недостатки: Подписка; риски; ограничения; сложность; утечки.
- Кому подходит: Для celebrity porn fakes.
✴ ✴ ✴
11. Mylovely
⭐️ Средняя оценка: 4.1/5
➡️ Lovely дипфейк русских знаменитостей порно

Романтические deep fake video.
- Преимущества: Эмоции; реализм; бесплатный; мобильный; гайды.
- Недостатки: Ограничения; этика; качество; нет 4K; базовый.
- Кому подходит: Для дип фейк порно русское.
✴ ✴ ✴
12. Seduced
⭐️ Средняя оценка: 4.5/5
➡️ Соблазняй в дип фейки знаменитостей порно
Седуктивные для deepfake porn celeb.

- Преимущества: Высокая частота; мимика; премиум; интеграция; скорость.
- Недостатки: Дорогой; риски; hardware; ограничения; юридические.
- Кому подходит: Профи в deepfake порно видео.
✴ ✴ ✴
13. Aiallure
⭐️ Средняя оценка: 4.4/5
➡️ Аллюр для дипфейк видео знаменитостей
Премиум для русский дипфейк порно.
- Преимущества: Качество; 3D; кастом; обновления; безопасность.
- Недостатки: Цена; сложность; этика; утечки; ограничения.
- Кому подходит: Для ххх фейк с звездами.
✴ ✴ ✴
14. CFake
⭐️ Средняя оценка: 4.0/5
➡️ Архив для russian deepfake porno

CFake - это давний архив фейковых изображений и видео знаменитостей, эволюционировавший от photoshop до deepfakes, с огромной коллекцией celeb fakes porn. Фокус на бесплатных галереях и клипах, где фанаты загружают контент вроде порно дип фейк знаменитости.
- Преимущества: Огромная база; бесплатный доступ после регистрации; разнообразие знаменитостей; еженедельные обновления; простота поиска.
- Недостатки: Устаревший дизайн; качество варьируется; в основном изображения; возможные интенсивные темы; отсутствие инструментов создания.
- Кому подходит: Любителям просмотра deepfake online creator без создания, особенно для дипфейк порно с русскими.
✴ ✴ ✴
15. AdultDeepFakes
⭐️ Средняя оценка: 4.5/5
➡️ Видео для порно дипфейк со звездами

Сайт с бесплатными high-quality deepfake видео знаменитостей, включая категории вроде Hollywood и K-pop, для celebrity deepfake porno.
- Преимущества: Регулярные обновления; высокое качество; разнообразные сценарии; бесплатный; сообщество.
- Недостатки: Нет создания; этические concerns; unfiltered контент; возможные overload; фокус только на просмотре.
- Кому подходит: Для просмотра celebrity nude fakes и deep nude fake.
Подводные камни в порно видео fake
Коротко сказать, что главные опасности — это утечка личных данных и вред реальным людям, — это только верхушка айсберга. На деле подводных камней в создании и потреблении дип фейк порно, фейк порно и deepfake порно гораздо больше, и они касаются почти всех аспектов: от технических до моральных и юридических.
Первое и самое ощутимое — конфиденциальность данных. Когда вы загружаете своё фото или видео на любой дипфейк сайт или пытаетесь сделать дипфейк порно онлайн, вы отдаёте биометрические данные в чужие руки. Многие платформы хранят файлы на серверах дольше заявленного срока, используют их для дообучения моделей или просто плохо защищают. Были случаи, когда базы утекали, и фото обычных людей оказывались в руках шантажистов или в даркнете. Даже если сервис честный и предлагает deepfake бесплатно, хакерская атака — это всегда риск. Поэтому многие эксперты советуют: никогда не загружайте фото с лицом, на котором видны родинки, шрамы или другие уникальные черты — их потом крайне сложно отследить и удалить, особенно если речь о фейк порно видео или deepfake porno video.
Второй огромный камень — жертвы манипуляций. Большинство deepfake sex, и дипфейки знаменитостей порно создаётся без согласия человека, чьё лицо используется. Это уже не просто «шутка» или «фантазия» — это форма цифрового насилия. Женщины (а иногда и мужчины), чьи лица вставляют в celebrity deepfake porn, порно фейки звезд видео или порно видео знаменитостей фейки, часто сталкиваются с травлей в соцсетях, потерей работы, разрывом отношений, депрессией и даже суицидальными мыслями. Известны громкие кейсы, когда знаменитости годами боролись с распространением таких роликов, а обычные люди вообще не имеют ресурсов для защиты. В 2025–2026 годах количество исков и жалоб на non-consensual deepfake porn videos, deepfake porn online и adult deep fake выросло в разы, но большинство стран всё ещё не имеют чёткого законодательства именно под эту проблему.
Третий аспект — юридические последствия для создателя. Даже если вы делаете фейк порно звезд, fake face porn или deep fake celebrity porn «для себя», но потом оно утекает (а утекает почти всегда через дип фейк бот тг или deepfake bot telegram), вас могут привлечь по статьям о распространении порнографии без согласия, клевете, нарушении неприкосновенности частной жизни. В некоторых юрисдикциях (США, ЕС, отдельные штаты Индии) уже ввели уголовную ответственность за создание и распространение non-consensual порно deepfake русское, deep fake porn russian и русский дипфейк порно. Штрафы доходят до сотен тысяч долларов, а в отдельных случаях — реальные сроки. При этом доказать, что вы «не распространяли», крайне сложно, если файл попал в сеть.
Четвёртый камень — качество и разоблачение. Многие думают, что их deep fake sex, дип фейк секс или дипфейки секс «идеальны», но современные инструменты детекции (Reality Defender, Microsoft Video Authenticator, Sentinel, Hive Moderation и др.) уже в 2026 году распознают 90–97% deepfake porn pov, porno deep fakes и deep porn fakes по микро-артефактам: неестественному движению зрачков, несоответствию освещения, асимметрии мимики, отсутствию естественных морщин при улыбке. Если ваш фейковое порно или фейк порно со знаменитостями попадёт в руки человека с доступом к таким инструментам (журналист, работодатель, обиженный партнёр), вас быстро вычислят.
Пятый — психологический и социальный вред для самого создателя. Многие, кто увлекается генерацией порно с дипфейком, порно с дипфейками или face swap порно, через какое-то время замечают, что перестают воспринимать реальных людей как реальных. Граница между фантазией и действительностью размывается, появляется зависимость от всё более экстремального deepfakes xxx, ххх фейк и xxx фейк контента. Плюс постоянный страх, что «а вдруг узнают, что это я делал». Это не шутки — в тематических сообществах полно историй выгорания и паранойи.
И наконец — репутационные и карьерные риски. Если ваш аккаунт, IP или метаданные когда-нибудь свяжут с созданием celebrity porno fake, porno fakes celebrity или celebrity deepfakes, это может закрыть двери в нормальную работу, особенно в сферах, связанных с детьми, образованием, госслужбой, медиа, IT-безопасностью. Работодатели всё чаще гуглят кандидатов глубже, включая даркнет и старые форумы.
Короче: то, что кажется безобидной забавой в приватном режиме, на деле — мина замедленного действия с кучей последствий для deep fake онлайн, deep fake online и дип фейк онлайн бесплатно. Лучше десять раз подумать, прежде чем загружать хоть одно своё фото.
Как выбрать генератор для celebrity porn fakes
Выбор сервиса для создания celebrity porn fakes и порно фейков со знаменитостями — это всегда компромисс между скоростью, качеством, ценой, безопасностью и этическими границами. Вот подробное сравнение, которое поможет принять осознанное решение.
Бесплатные сервисы и пробные версии
Плюсы:
- Ноль или почти ноль затрат на старте для deepfake порно онлайн или deepfake porn online.
- Можно быстро протестировать 5–10 разных платформ за вечер и понять, как работает онлайн дипфейк.
- Часто дают 3–10 бесплатных генераций или кредитов при регистрации для deepfake бесплатно.
- Не нужно вводить карту, меньше риска слить платёжные данные при попытке создать порно фейк.
Минусы:
- Качество обычно среднее или ниже среднего (deep fake porn video в 720p, заметные артефакты на движении, плохой lip-sync в deepfake porno video).
- Почти всегда ставят водяные знаки или логотип сервиса на фейк порно видео.
- Ограничение по времени обработки — иногда ждёшь в очереди 20–60 минут для дип фейк видео.
- Сильно урезанный функционал: нельзя выбрать модель, освещение, позу, нельзя дообучать для дипфейки знаменитости порно.
- Высокий риск утечки данных — бесплатные платформы чаще всего зарабатывают именно на продаже загруженных фото для fake face порно.
- Реклама, поп-апы, редиректы на сомнительные сайты с фейковое порно звезд.
Когда стоит выбрать бесплатный вариант:
- Вы просто любопытствуете и хотите понять, как это вообще работает в порно дипфейк онлайн.
- Нужен один-два тестовых результата «для себя» в deep fake online.
- Нет желания тратить деньги на то, что может не понравиться в лучшие дипфейки порно.
- Вы морально готовы к тому, что результат будет «на троечку» для порно фейки актрисы.
Премиум / платные подписки
Плюсы:
- Качество на голову выше: 4K, плавное движение, хороший lip-sync, правильные тени и отражения, естественная мимика в deepfake porn videos.
- Нет водяных знаков (или их можно убрать) на best deepfake porn.
- Приоритет в очереди — генерация за 30–120 секунд вместо часов для дип фейк порно со звездами.
- Доступ к продвинутым настройкам: выбор освещения, ракурса, позы тела, одежды/ню, дообучение на своих датасетах для deepfake russian porn.
- Часто есть мобильное приложение или удобный веб-интерфейс без лагов для deep fake порно.
- Лучшая заявленная политика конфиденциальности (хотя доверять на 100% всё равно нельзя) при создании deep fake porn russian.
- Регулярные обновления моделей, поддержка новых трендов (например, улучшенный порно deepfake русское).
Минусы:
- Цена: от $9–15/месяц за базовый премиум до $50–100 за топ-тарифы с неограниченными генерациями porno fakes.
- Нужно привязывать карту — всегда риск автоматического списания после триала для дип фейк сделать онлайн.
- Некоторые сервисы требуют верификации (паспорт, селфи) — это уже серьёзный красный флаг для приватности в deepface xxx.
- Если сервис закроется или сменит политику, ваши кредиты/подписка могут сгореть при работе с порно с лицами звезд.
- Выше риск, что именно премиум-аккаунты чаще попадают под аудит правообладателей и блокируются за celebrity deepfakes.
Практические советы по выбору
- Сначала протестируйте 3–5 бесплатных/триальных версий deepfake video online.
- Сравните результаты по одним и тем же фото/видео: смотрите на глаза, губы, переход шея-лицо, движение волос в deepfake порно онлайн.
- Читайте свежие отзывы на Reddit (r/DeepFakes, r/AIporn, r/NSFW_AI), Telegram-каналы и форумы — там быстро всплывают, кто начал плохо обрабатывать данные или резко ухудшил качество порно фейки со звездами.
- Ищите сервисы с end-to-end шифрованием и политикой «no log / no store» для дип фейк онлайн видео.
- Никогда не используйте одно и то же лицо на нескольких платформах — это увеличивает шанс утечки фейк порно со звездами.
- Если цель — максимальный реализм для celebrity deepfake porn, porno deep fakes и deep porn fakes, то обычно побеждают платные сервисы с собственными дообученными моделями на больших датасетах знаменитостей.
Итог: бесплатные — для первого знакомства и экспериментов с deep fake sex, премиум — для тех, кто хочет действительно крутой результат и готов платить за скорость, качество и (относительную) приватность в дипфейк порно онлайн. Но помните: даже самый дорогой сервис не даёт 100% гарантии, что ваше лицо и фантазии останутся только у вас при создании порно с дипфейком.
FAQ про deepfakes porno video
Как безопасно создать sex fake? Выбирайте сервисы с шифрованием.
Что с юридическими аспектами celeb fakes porn? В 2026 законы строже для неконсенсусного.
Бесплатные варианты для russian deepfake porno? Да, но с лимитами.
Как улучшить качество в deepfake online creator? Используйте хорошие датасеты.
Альтернативы для порно дипфейк со звездами? Мобильные apps с face swap.
Поисковая выдача меняется быстрее, чем большинство SEO-команд успевают переписать свои чек-листы. Пока одни продолжают воевать за CTR в Google, другие уже оптимизируют тексты под языковые модели. И это не футуризм. AI-поиск начал формировать новый тип контента: не для роботов-индексаторов, а для систем, которые пересказывают, цитируют и агрегируют смысл. Ниже — разбор того, как меняется архитектура текста, почему старые SEO-паттерны ломаются и какие статьи нейросети начинают считать надёжным источником.
Google ищет страницы. Нейросети ищут фрагменты смысла
Последние двадцать лет SEO строилось вокруг документа. У страницы был title, H1, плотность терминов, ссылки, поведенческие факторы. Поисковик ранжировал URL.
Большие языковые модели работают иначе. Для них статья — не страница, а набор смысловых блоков.
Условный ChatGPT или Perplexity не думает категориями «лучший сайт». Он пытается найти наиболее устойчивый и логически связанный ответ внутри огромного массива текста. Иногда это один абзац. Иногда таблица. Иногда короткое объяснение между двумя подзаголовками, которое автор вообще написал почти случайно.
В этом и начинается проблема классического SEO.
Многие статьи отлично ранжируются, но абсолютно бесполезны для AI-поиска. Они раздуты, перегружены вводными конструкциями и не содержат плотных смысловых единиц. Для нейросети такой текст выглядит как шум с рекламными вставками.
Характерный пример появился ещё в 2024 году, когда Perplexity начал активно использовать внешние источники в ответах. В ряде ниш выяснилась странная вещь: AI стабильно цитировал не самые крупные сайты, а небольшие технические блоги с плотной экспертизой.
Особенно это было заметно в темах:
- DevOps
- AI engineering
- Kubernetes
- reverse engineering
- low-level backend
- информационная безопасность
Причина оказалась простой. Маленькие инженерные блоги писали тексты так, как люди реально объясняют проблему друг другу. Без SEO-прокладок на четыре тысячи слов.
Нейросеть это «понимала» лучше поисковика.
Почему 90% AI-сгенерированного контента никогда не будет цитироваться
В AI-поиске появилась новая метрика, которую SEO-индустрия пока плохо осознаёт: semantic compression ratio.
Если объяснять по-человечески — это количество полезного смысла на единицу текста.
У большинства AI-статей этот показатель чудовищно низкий.
Текст выглядит гладким. Грамматика идеальная. Подзаголовки аккуратные. Но внутри почти нет новых связей между сущностями. Нейросети быстро распознают такой паттерн, потому что сами производят его миллионами копий.
Получается почти комичная ситуация: AI начинает игнорировать тексты, которые были написаны AI по шаблонам SEO.
Особенно плохо работают статьи:
- с чрезмерно «правильной» структурой
- с одинаковой длиной абзацев
- с предсказуемыми переходами
- с универсальными вводными конструкциями
- с отсутствием конфликтов и неожиданных мыслей
- с безопасными формулировками без конкретики
Условно говоря, если текст можно сократить на 70% без потери смысла — это плохой кандидат для AI-цитирования.
Сейчас языковые модели начинают сильнее доверять материалам, где есть:
- реальные ограничения
- противоречия
- субъективные наблюдения
- технические детали
- редкие термины
- конкретные цифры
- нестандартные кейсы
В инженерной среде это давно заметили. Например, документация PostgreSQL часто цитируется AI лучше, чем сотни SEO-статей вокруг неё. Хотя визуально она выглядит скучно и тяжело.
Потому что там высокая плотность проверяемого смысла.
Как меняется структура статьи под AI-поиск
Самое интересное — AI-поиск начал ломать старую модель storytelling в контенте.
Раньше статья строилась как последовательный маршрут: введение → проблема → решение → вывод.
Теперь это работает хуже.
Языковые модели редко читают текст линейно. Они извлекают куски. Иногда из середины. Иногда из списков. Иногда из подписи к изображению.
Из-за этого начали меняться даже технические подходы к написанию материалов.
В хороших AI-friendly статьях появляется так называемая fragment architecture — структура автономных смысловых секций.
Каждый блок должен:
- работать отдельно от всей статьи
- содержать завершённую мысль
- быть понятным без контекста соседнего абзаца
- иметь высокую терминологическую точность
Это особенно заметно в документации Stripe, Cloudflare, Anthropic и некоторых инженерных блогах OpenAI-подрядчиков. Там абзацы становятся короче, но смысл внутри — плотнее.
Иногда статья выглядит почти «рваной». И это нормально.
Для AI такая структура удобнее.
Ещё одна неожиданная тенденция — снижение роли красивых переходов. Классическая журналистская связность перестаёт быть преимуществом.
По сути AI-поиск предпочитает тексты, похожие на хорошо организованную инженерную доску в Notion, а не на лонгрид из медиа 2018 года.
Entity-first контент: почему нейросети любят статьи с нормальными сущностями
У поисковиков давно были entity-графы. Но языковые модели используют сущности значительно агрессивнее.
Для AI важно не только слово, но и сеть связей вокруг него.
Если статья упоминает:
- CUDA
- inference latency
- quantization
- token window
- vector database
- retrieval pipeline
…то модель начинает понимать контекст уровня системы, а не набора ключей.
Проблема в том, что многие SEO-тексты до сих пор пишутся через абстрактные категории.
Типичный пример:
«Современные AI-инструменты помогают бизнесу автоматизировать процессы».
Такой фрагмент почти бесполезен.
Нормальный AI-first текст будет выглядеть иначе:
«После перехода с GPT-3.5 Turbo на Mixtral 8x7B latency inference в customer support pipeline снизился примерно на 18%, но вырос объём hallucinations в длинных диалогах».
Во втором примере появляются:
- сущности
- отношения между ними
- измеряемость
- технический контекст
- причинно-следственная связь
Именно такие фрагменты нейросети начинают считать цитируемыми.
Иногда достаточно одного сильного абзаца, чтобы модель начала воспринимать сайт как источник экспертизы.
Любопытно, что это уже влияет даже на стиль редактур. Некоторые западные AI-медиа начали специально удалять «SEO-разбавление» из статей перед публикацией.
То, что раньше называли readability optimization, постепенно становится проблемой.
Почему AI-поиск неожиданно вернул ценность авторского стиля
Самый парадоксальный эффект AI-эпохи — рост ценности человеческой неровности.
Ещё два года назад многие думали, что контент окончательно станет стерильным. Но произошло обратное.
Языковые модели начали хуже доверять идеально усреднённому тексту.
Внутри индустрии retrieval systems уже обсуждается эффект synthetic flattening — ситуация, когда интернет начинает заполняться одинаковыми AI-паттернами, и модели теряют способность различать качество источников.
На этом фоне выигрывают тексты с:
- живой терминологией
- странными наблюдениями
- локальными деталями
- авторскими формулировками
- естественными шероховатостями
Особенно хорошо это видно в Reddit-цепочках и старых инженерных форумах. Иногда нейросеть достаёт комментарий пятилетней давности с тремя лайками вместо «оптимизированной» статьи крупного медиа.
Потому что комментарий содержит реальный опыт.
В AI-поиске доверие начинает формироваться не через polished-контент, а через ощущение настоящего источника.
И это, пожалуй, главный слом всей старой SEO-модели.
Что произойдёт дальше
Скорее всего, ближайшие два года станут периодом странного сосуществования двух интернетов.
Первый — старый SEO-веб, где всё ещё важны позиции, сниппеты и CTR.
Второй — AI-layer поверх интернета, где выигрывает уже не страница, а извлекаемый смысл.
Многие сайты начнут терять поисковый трафик не потому, что стали хуже, а потому что их тексты неудобны для retrieval-систем.
Особенно болезненно это ударит по контентным фермам и агентствам, производящим поток одинаковых материалов.
При этом вырастет ценность:
- технической экспертизы
- плотного контента
- инженерного стиля письма
- уникальных наблюдений
- текстов с высокой semantic depth
Парадоксально, но AI-поиск может вернуть интернету то, что массовое SEO почти уничтожило: тексты, написанные людьми с опытом, а не контентными конвейерами.
Ирония в том, что нейросети внезапно начали ценить в текстах именно человеческое присутствие.