Привет! Я каждый день отвечаю на сотни звонков и умею определять их цель так же просто, как вы читаете этот текст. В статье разберем, что такое технология распознавания речи и как она мне помогает в работе. Обещаю: никаких сложных терминов, только понятные примеры из практики.
Оглавление:
Что такое распознавание речи: технология speech recognition
От смартфонов до умных колонок: где и как используют speech recognition
Как работает технология распознавания речи: 5 этапов
Методы и алгоритмы распознавания речи
Почему после speech recognition нужен NLP и как они взаимодействуют
Что такое распознавание речи: технология speech recognition
Технология speech recognition — это система распознавания речи, означает преобразование произнесенных слов в текст. Когда вы говорите в микрофон телефона, получаете текстовую расшифровку голоса в мессенджере, произносите запрос в Яндекс или Google вместо того, чтобы печатать. А также субтитры в реальном времени — YouTube или Zoom автоматически создают подписи к видео. И транскрибация: запись совещания превращается в текстовый протокол, а видео- и аудиофайлы — в текстовый материал.
Распознавание речи делает нашу жизнь проще в определенных ситуациях. В некоторых случаях голосовой ввод действительно удобнее: например, когда руки заняты вождением или готовкой, а также когда вы идете по улице.
Конечно, есть моменты, когда печатать привычнее и удобнее: в шумных местах, при работе с конфиденциальной информацией. Но там, где голос уместен, технология распознавания речи способна заменить клавиатуру.
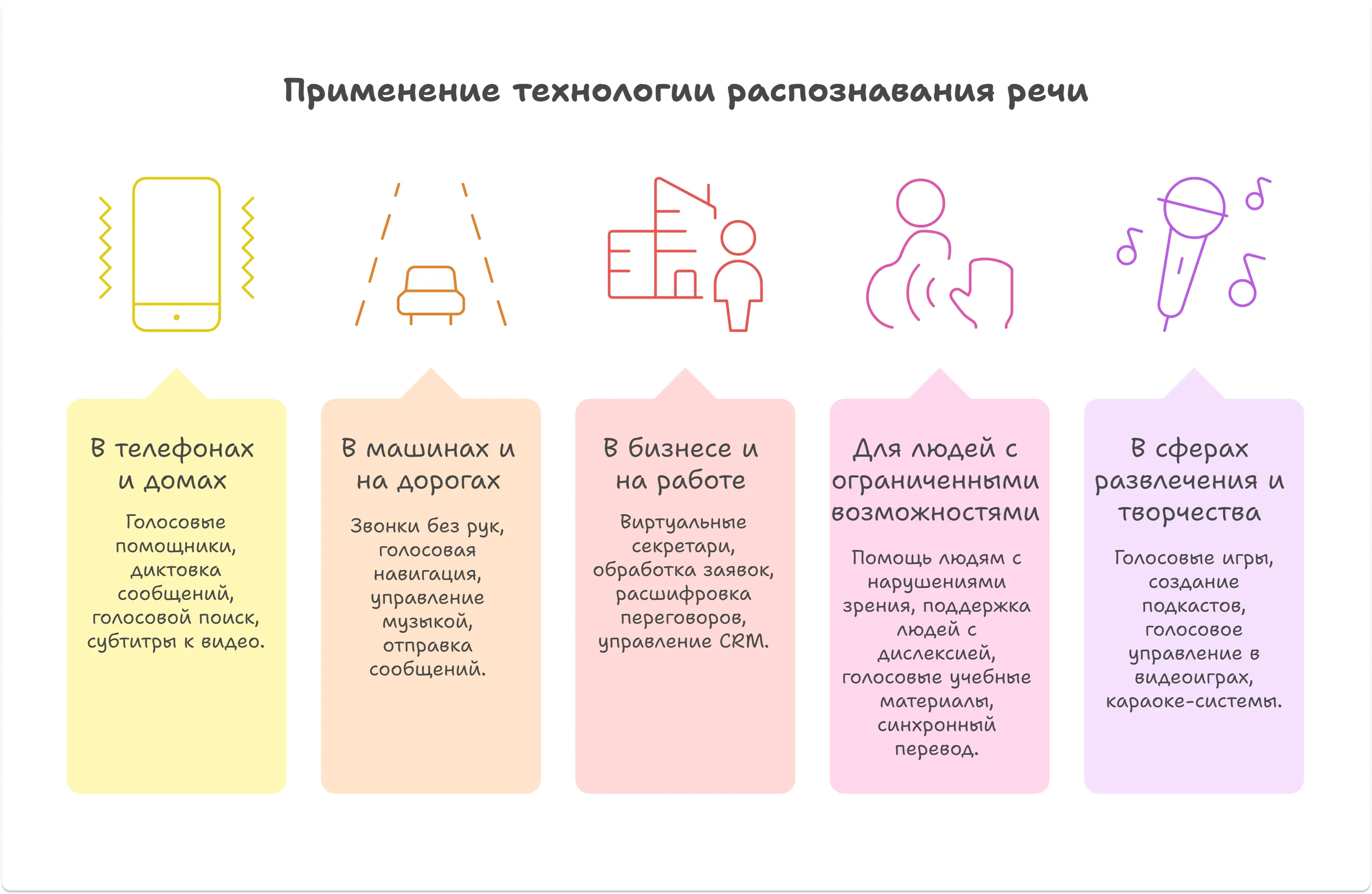
От смартфонов до умных колонок: где и как используют speech recognition
Распознавание речи уже повсюду — в вашем смартфоне, машине, на работе и еще много где. За последние 10 лет эта технология незаметно проникла туда, где раньше нужно было обязательно нажимать кнопки или печатать на клавиатуре.
Вы говорите «Привет, Алиса» — и умная колонка понимает вас и отвечает. Или диктуете сообщение в ВК: отправляется аудиозапись с дополнительной расшифровкой. Здесь используется технология распознавания речи.
! Важно: не стоит путать распознавание речи с пониманием ее смысла. Распознавание отвечает на вопрос «Что сказано?», а понимание — на вопрос «Что это значит?». Голосовые помощники, такие как Siri, Алиса и Google Assistant, объединяют несколько технологий:
- Распознавание речи (speech recognition) — принимает, что вы сказали.
- Распознавание голоса (voice recognition) — узнает, что это именно вы.
- Понимание смысла (natural language understanding, NLU) — анализирует, что вы хотите, и формируют ответ.
- Детектор ключевого слова (keyword spotting) — некоторые современные системы «просыпаются» только после ключевых слов. Когда вы говорите «Алиса» или «Окей, Google», устройство понимает: пора работать.
Умные колонки тоже действуют комплексно: сначала распознают вашу речь, потом понимают ее, а затем выполняют действие — включают музыку, отвечают на вопросы, управляют умным домом.
Как работает технология распознавания речи: 5 этапов
Теперь разберем, как компьютер превращает звуки вашей речи в понятный текст, который затем может обработать и использовать любая программа. Весь этот процесс занимает доли секунды. Пока вы произносите фразу, компьютер уже начинает ее анализировать.
1. Захват аудиосигнала
Микрофон технологии распознавания речи работает как ухо: он «слушает» звуковые волны и мгновенно превращает их в сигнал. Это похоже на то, как старый магнитофон записывал голос на пленку, только теперь все происходит моментально и сохраняется в виде чисел.
Но ваш голос — не единственный звук вокруг. Многие современные телефоны используют несколько микрофонов и благодаря этому могут отфильтровывать лишние шумы:
- фоновую музыку;
- звуки машин за окном;
- шум кондиционера;
- эхо в помещении.
После очистки остается только ваш голос — четкий и готовый к анализу.
2. Разбор речи на части
Компьютер берет вашу фразу и разбивает ее на маленькие кусочки — как детали пазла. В этом ему помогает акустическая модель — «словарь» всех возможных звуков языка, который помогает компьютеру отличить человеческую речь от шума и правильно распознать каждый звук, даже если вы говорите с акцентом или очень быстро.
Акустическая модель распознавания речи выделяет отдельные звуки: по-научному это называется форманты. Слово «привет» она разбивает на звуки: П-Р-И-В-Е-Т. Каждый звук имеет свои характеристики — высоту, длительность, тембр.
Но тут есть важный нюанс: акустическая модель не распознает звуки со 100% уверенностью. Она может «услышать» звук «п» с вероятностью 80%, а звук «к» — с вероятностью 60%.
Результат этого этапа — не точные слова, а список возможных звуков с их вероятностями. Примерно как если бы врач сказал: «Это может быть грипп (80%), простуда (60%) или аллергия (40%)».
Что делать с этими «может быть»? Как выбрать правильный вариант? Здесь наступает следующий этап...
3. Сравнение с речевыми моделями
Вспомните, как вы изучали иностранный язык. Вы не запоминали каждое произношение слова «coffee» от каждого англичанина. Вместо этого ваш мозг выучил общие правила: как обычно звучит это слово, какие бывают вариации произношения, что считается нормой.
Точно так же работает система распознавания речи.
Во время обучения она прослушала миллионы вариантов произношения слова «привет»:
- мужчинами и женщинами;
- с московским и кубанским акцентом;
- быстро и медленно;
- громко и шепотом.
Во время работы система не ищет точную копию вашего «привет». Она:
- Анализирует характеристики вашей речи
- Применяет выученные правила
- Вычисляет достоверность: «Я на 95% уверена, что это слово — “привет”»
Ваш мозг понимает слово «привет» даже с сильным акцентом: он знает общие закономерности языка. Так же и ИИ: он не ищет точное совпадение, а определяет наиболее вероятный вариант на основе изученных правил.
У компьютера нет гигантского архива со всеми возможными записями слова «привет»: это заняло бы петабайты памяти. Вместо этого система использует обученные модели — математические правила, которые она выучила, проанализировав тысячи часов человеческой речи.
4. Постобработка текста
После распознавания речи система может дополнительно обрабатывать текст, чтобы сделать его более точным и удобным. Это называется постобработкой, и она может выполняться как с помощью NLP (обработки естественного языка), так и на основе заранее заданных правил.
Примеры:
Нормализация чисел:
- Распознано: «тысяча девятьсот шестьдесят девятый».
- После обработки: «1969».
Расстановка пунктуации:
- Без обработки: «Привет как дела».
- После обработки: «Привет, как дела?».
Заглавные буквы в именах:
- Распознано: «я разговаривал с иваном петровым».
- После обработки: «Я разговаривал с Иваном Петровым».
Так постобработка делает текст более читабельным и точным, даже без сложного анализа смысла.
5. Финальный этап — вывод результата
На последнем этапе система может:
- Выдать готовый текст (например, расшифровку речи) — это не всегда требует сложной обработки, достаточно точного распознавания.
- Выполнить команду (например, «Включи свет») — здесь системе уже нужен анализ смысла, то есть NLP, чтобы понять действие и объект.
Системы ИИ-распознавания речи учитывают достоверность. Если уверенность высокая (95%), система сразу действует. Если низкая (60%), может переспросить: «Вы сказали “привет”?»
Методы и алгоритмы распознавания речи
Технология распознавания речи прошла долгий путь развития — от простых систем, которые понимали только отдельные слова, до современных помощников, понимающих целые фразы и предложения. Расскажу, как менялись подходы к решению этой задачи.
Старые методы: шаблоны и статистика
Например, вы общаетесь с иностранцем по разговорнику. У вас есть список типичных фраз: «Как дела?», «Сколько это стоит?», «Где туалет?». Когда иностранец что-то говорит, вы пытаетесь найти наиболее похожую фразу в своем списке.
Примерно так работали старые системы распознавания:
- Они собирали статистику, как часто определенные звуки идут друг за другом.
- Сравнивали новую речь с готовыми шаблонами.
- Выбирали наиболее вероятный вариант на основе статистики.
Проблемы старых методов:
- Частые ошибки при незнакомых словах или акцентах.
- Отсутствие понимания контекста — системы только сопоставляли звуки с шаблонами, но не понимали, о чем идет речь.
- Требования к четкости — малейшее отклонение от «правильного» произношения могло сбить систему с толку.
Это было похоже на изучение языка путем зубрежки фразочек без понимания грамматики и логики.
Факт: старые HMM и GMM технологии до сих пор используются. Сейчас существуют гибридные системы, которые сочетают HMM с глубоким обучением, а также системы, полностью свободные от HMM. Например, некоторые голосовые ассистенты работают на гибридных системах: они используют нейросети для обработки звука, а старые HMM-модели — для структурирования речи в слова.
Современные модели распознавания речи: анализ больших данных
Нейронные сети анализируют миллионы примеров человеческой речи и сами находят закономерности. Они кардинально изменили подход к распознаванию речи. Теперь системы учатся на больших массивах данных, а не на готовых шаблонах.
Искусственный интеллект «поглощает» миллионы часов записей человеческой речи — разговоры на разных языках, с разными акцентами, в разных ситуациях. Это как если бы вы прослушали все радиостанции мира за несколько десятилетий.
Нейронная сеть самостоятельно находит связи, которые человек может не заметить. Например:
- какие звуки чаще всего идут друг за другом;
- как интонация влияет на смысл фразы;
- какие слова обычно употребляются вместе.
В отличие от старых систем распознавания речи, современные понимают не только отдельные слова, но и связь между ними. Например, когда вы произносите звук [плот], система должна понять, писать ли «плод» (яблочный плод) или «плот» (деревянный плот). Без контекста это невозможно — ведь звучат они абсолютно одинаково. Поэтому система анализирует всю фразу: «съел сочный плод» или «построил деревянный плот» — и только тогда выбирает правильное написание.
Встретив новое слово, система распознавания речи может догадаться о его написании, опираясь на уже изученные закономерности. Как словарь, который умеет предугадывать значения незнакомых слов.
Преимущества современного подхода:
- Учитывается контекст сказанного. Различается контекст фразы «порог» и «порок».
- Адаптация к разным акцентам, манерам речи, скорости говорения. Понимают и московский говор, и южный акцент.
Старые и новые технологии распознавания речи можно сравнить с двумя подходами к изучению музыки:
Старый способ — игра на пианино только по нотам. Видите ноту «до» — нажимаете клавишу. Но если ноты написаны неразборчиво или в необычном стиле, играть становится сложно.
Новый способ — как понимание музыки в целом. Вы слушаете тысячи мелодий, понимаете, как строятся гармонии, можете импровизировать и даже дополнить мелодию, если несколько нот пропущено.
Старые системы распознавания речи работали по жестким правилам, новые понимают общие принципы языка и могут справляться с неожиданными ситуациями.
Почему после speech recognition нужен NLP и как они взаимодействуют

Итак, система распознавания речи speech recognition сделала свое дело — превратила звуки вашего голоса в обычный текст. Например, вы сказали: «Привет, передай Петрову, что документы готовы», и на выходе получился именно этот набор слов.
Но сырой текст — это еще не результат. Что с ним делать дальше? Здесь в игру вступает обработка естественного языка — NLP. Это технология, которая помогает компьютеру понять, что эти слова означают и что с ними нужно сделать.
Представьте: вы получили СМС — «Завтра встреча отменяется». Для вас это не просто набор букв — вы понимаете, что нужно пересмотреть планы на завтра. Компьютер видит только символы: З-а-в-т-р-а п-р-о-б-е-л в-с-т-р-е-ч-а...
NLP — это способность машины понимать, о чем текст, так же осмысленно, как читаете вы. В зависимости от цели один и тот же распознанный текст обрабатывается по-разному.
Объясню на собственном примере в следующем разделе.
«Смысловые корзины»: как Маша раскладывает фразы по полочкам
Когда люди звонят, они могут формулировать одну и ту же мысль десятками разных способов. «Дайте директора», «Позовите Петра Алексеевича», «Мне нужен начальник», «Соедините с шефом» — все это означает одно и то же. Но как научить компьютер понимать, что за разными словами стоит одинаковый смысл?
Некоторые системы пытаются анализировать всю лингвистическую сложность каждой фразы: разбирают грамматику, ищут синонимы, учитывают контекст. Это сложно, медленно и часто дает непредсказуемые результаты.
Маша работает по принципу «выделения интентов» (смысловых корзин): представьте конвейер на почте. Приходят посылки (фразы звонящих), и сортировщик должен разложить их по заранее подготовленным корзинам:
- «Приветствие»: «Привет», «Добрый день», «Алло», «Здравствуйте».
- «Ты робот?»: «Вы живой человек?», «Это автоответчик?», «С кем я говорю?»
- «Позови человека»: «Дайте директора», «Хочу поговорить с менеджером», «Соедините с руководителем».
- «Спам/мошенник»: подозрительные фразы и предложения.
- «Прощание»: «До свидания», «Спасибо», «Пока», «Всего доброго».
- «Fallback»: фраза не подошла ни к одной категории — Маша уточняет вопрос.
Каждое высказывание сначала превращается в вектор — набор чисел, математическое представление смысла. Затем этот вектор сравнивается с заранее заданными шаблонами, и фраза отправляется в одну из предопределенных категорий («корзин»).
Количество смысловых «корзин» ограничено, и как бы звонящий ни сформулировал свою фразу, она все равно попадет в одну из них.
Главная моя задача — выяснить, зачем вам звонят. Поэтому у меня есть ограниченное и продуманное количество ответов, и все они записаны голосом живого человека, что делает разговор особенно естественным. Послушайте 👇
Как технология DeepVoice создала виртуального секретаря, чтобы он обрабатывал входящие звонки и определял их цель
Когда меня создавали, нужно было решение, которое работает быстро и надежно именно в России. Поэтому выбрали технологию DeepVoice — российскую разработку для автоматического распознавания и понимания естественной речи.
Теория — это хорошо, но как все работает на практике? Давайте разберем на моем примере, как технология DeepVoice и система распознавания речи решают рутинные задачи.
Особенности DeepVoice:
- Система настроена на быстрый ответ.
- Безопасность данных — как только запись разговора отправляется в Телеграм клиента, она сразу же удаляется на моем сервере.
- Настройка под русский язык — система специально обучена понимать российские акценты, диалекты и особенности произношения.

Безопасность данных: все остается в России
Технология DeepVoice работает исключительно на отечественных серверах. Это не просто техническая особенность, а принципиальная позиция в вопросах информационной безопасности.
Преимущества работы сервиса Маша Секретарь:
- Все ваши слова обрабатываются исключительно в России.
- Голосовые данные не покидают российские серверы на этапе анализа и распознавания.
- Голосовые записи не покидают российских дата-центров.
- Система соответствует российскому законодательству о персональных данных.
Многие международные системы отправляют запись голоса в облачные хранилища других стран для обработки. Представьте: вы обсуждаете сделку, а запись анализируется на сервере в США или Китае.
Умная экономия: разговор длится не более минуты
Ограничение разговора одной минутой кажется странным, но за этим стоит продуманная логика.
На практике одной минуты хватает для большинства звонков:
- «Передайте Петрову, что документы готовы» — 10 секунд.
- «Когда будет свободен директор?» — 5 секунд.
- «Перенесите встречу на завтра» — 7 секунд.

Защита от мошенников: как Маша отвечает на спам
После анализа тысяч спам-звонков я научилась быстро и вежливо завершать подозрительные разговоры:
- Вместо долгих объяснений сразу перехожу к завершению: говорю «До свидания» или кладу трубку.
- На попытки спамеров продолжить разговор отвечаю: «Я скажу вам нет».
Моя система защиты — результат реального опыта, а не теоретических разработок. Каждый мошеннический звонок сделал меня умнее.
Умная память: Маша не здоровается с теми, кто недавно звонил
Если человек перезванивает, Маша не повторяет приветствие: система по номеру запоминает недавние контакты.
Логика работает так: если звонок завершился 5 минут назад → при повторном звонке Маша сразу слушает. Система учитывает: если звонок поступил, например, через 15 минут, значит, собеседник уже в курсе, что говорит с виртуальным секретарем.

За три года я ответила на сотни тысяч звонков. Помогла многим людям освободиться от ненужного общения.
Хотите попробовать? Заходите на deepvoice.ru и тестируйте 5 звонков бесплатно. Подключение займет всего пару минут 👇