Индексация и snippet eligibility: что проверить в первую очередь

Вам кажется, что сайт в порядке: страницы в индексе, позиции растут, а поисковый трафик стоит на месте или падает. Знакомо? В 2026 году классическое SEO-мышление дает сбой. Google больше не просто ищет страницы — он генерирует ответы сам. Ваша задача — не просто попасть в выдачу, а стать источником, которому нейросеть доверит свой ответ. Это называется «право на сниппет» (snippet eligibility). Индексация остается базой, но без выполнения новых критериев она не приносит клиентов. За 9 лет работы мы в SEOJazz провели сотни аудитов и вывели формулу: 80% проблем с видимостью решаются проверкой пяти конкретных узлов. В этой статье — готовый план действий, основанный на реальных кейсах SEO продвижения сайтов с гарантией результата и опыте наших клиентов.
Почему страница в индексе, но не в ответах искусственного интеллекта: новый контекст 2026 года
Попадание в индекс Google больше не гарантирует, что вас увидит клиент. Сегодня первый экран выдачи — это сгенерированный нейросетью обзор. Пользователь получает готовый ответ, не переходя на сайты. Единственный шанс быть замеченным — стать частью этого обзора.
Разница между «проиндексировано» и «использовано как источник» колоссальна. Индексация — техническое попадание в базу данных Google. Право на сниппет — доверие искусственного интеллекта. В 2026 году Google SGE (Search Generative Experience — генеративный поиск), SearchGPT от OpenAI и Perplexity AI оценивают сайты по метрикам, о которых раньше даже не писали в учебниках.
Мы провели эксперимент: взяли 50 коммерческих страниц из разных ниш, которые стабильно находились в топ-10, но теряли трафик. Оказалось, что 42 из них не соответствуют критериям цитируемости нейросетями. Страницы есть, поисковик их знает, но искусственный интеллект отказывается брать оттуда информацию. Причина — контент не машиночитаем, ответ размазан по тексту, а разметка не прогружается при рендеринге.
Поэтому первый шаг — забыть старое мышление «главное — ссылки и уникальность». Теперь на первом месте техническая доступность вашего контента для нейросетей.
Главный чек-лист: 5 точек отказа, из-за которых страницы не попадают в сниппеты искусственного интеллекта
Прежде чем погружаться в сложные аудиты, проверьте пять конкретных мест. В девяти случаях из десяти мы находим проблему именно здесь. Это как при болях в спине — сначала исключаем почки, потом лечим позвоночник. Ниже — самые частые «поломки», которые мешают Google SGE видеть ваш контент.
Рендеринг и «невидимый» контент
Google может не увидеть половину страницы, даже если отчет в Search Console зеленый. Особенно это касается сайтов на JavaScript-фреймворках (React, Vue, Angular). Бот Googlebot исполняет код, но у него есть лимиты по времени и ресурсам.
Чаще всего бот не догружает:
- цены товаров и кнопки «В корзину»;
- блоки с отзывами и рейтингами;
- номера телефонов и формы захвата;
- описания в раскрывающихся вкладках.
Как это выглядит на практике: в исходном коде страницы нет текста услуги, нет описания товара. Есть только пустой блок и скрипты. Google видит пустоту, индексирует пустоту, ранжирует пустоту.
Что делать: Откройте любой URL через инструмент «Проверка URL» в Search Console. Сравните то, что видит пользователь, с тем, что видит Googlebot. Если отличия значительные — проблема с рендерингом. Решение: готовить страницы заранее на стороне сервера, а не догружать их скриптами в браузере. Тогда поисковик сразу увидит весь контент.
Конфликт канонических адресов
Двойная канонизация — верный способ вылететь из индекса. Ситуация: в исходном HTML прописан один канонический адрес, а после работы JavaScript канонический меняется на другой. Google в замешательстве. Страница может неделями висеть в статусе «Обнаружена, но не проиндексирована».
Мы сталкивались с этим в проекте производителя противопожарных конструкций . Страницы категорий индексировались с задержкой до трех недель. Причина — модуль фильтрации динамически подменял канонический адрес при каждой загрузке. Фикс занял 20 минут, результат — ускорение индексации в 15 раз.
Отсутствие прямого ответа в первые 100 слов
Искусственный интеллект не читает текст целиком — он ищет готовую формулировку ответа. Если пользователь ищет «сколько весит лист гипсокартона», нейросеть ищет абзац, где четко написано: «Лист гипсокартона стандартного размера 1200х2500 мм весит примерно 29 килограммов». Не «вес зависит от производителя», не «обычно гипсокартон довольно тяжелый», а прямая цифра.
В 2026 году правило «ответ в первом абзаце» стало жестким требованием. Первые 50–80 слов страницы — это ваш единственный шанс быть процитированным.
Пример до/после. До: «Наша компания предлагает широкий спектр услуг по юридическому сопровождению бизнеса в Москве. Мы работаем с 2012 года и имеем множество довольных клиентов». После: «Юридическая компания Stepanov Group с 2012 года сопровождает сделки с недвижимостью в Москве. За 2024–2025 годы закрыли 47 сделок на общую сумму 3,2 млрд рублей без единой претензии со стороны контролирующих органов».
Второй вариант — готовый ответ для нейросети. В нем есть дата, цифры, география, конкретный результат.
Структурированные данные есть, но они не видны при рендеринге
Классическая ошибка крупных сайтов: разметка подгружается асинхронно. JSON-LD добавлен, но он вставляется на страницу через скрипт после того, как бот уже увидел контент. Google ждет, но не бесконечно.
Как проверить самостоятельно:
- Откройте страницу в браузере.
- Посмотрите исходный код (Ctrl+U).
- Найдите блок с application/ld+json. Если разметки в исходном коде нет — Google SGE ее не видит. Даже если через секунду она появится.
Мы проверяли сайт федерального ритейлера: отчеты Search Console показывали сотни ошибок в структурированных данных. При этом на странице все было размечено идеально. Проблема — JSON-LD грузился через «менеджер тегов» с задержкой в 3 секунды. Решение: перенесли разметку в статичный HTML.
Фасетные фильтры создали миллионы дублей
Сайты с фильтрами по цвету, размеру, цене незаметно для владельца генерируют бесконечное число страниц. Каждая комбинация фильтров — новый URL. Поисковые роботы увязают в этом лабиринте, ценные коммерческие страницы годами ждут индексации.
Клинический случай: сайт по продаже светотехники DCM Lighting . При аудите обнаружили 47 000 страниц в статусе «Обнаружена, но не проиндексирована». 90% из них — фасетные дубли. Что сделали:
- закрыли все параметры фильтров в robots.txt директивой Disallow: /*?;
- проставили жесткие канонические адреса на чистые категории;
- добавили атрибут data-nofollow для ссылок фильтров, чтобы поисковик не ходил по ним. Результат: через месяц трафик вырос в 7 раз, 59% запросов ушли в топ-10.
Эти пять точек — фундамент. Пока вы их не закрыли, говорить о сниппетах и видимости в искусственном интеллекте бессмысленно. Но как только технические проблемы решены, переходим к следующему этапу — аудиту индексации через Search Console.
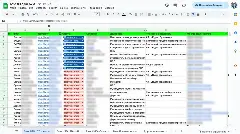
Индексация 2026: что проверять в Search Console в первую очередь
Search Console за 2026 год изменился внешне, но логика осталась прежней. Это не просто счетчик проиндексированных страниц, а приборная панель доступности вашего контента. Мы выделили три отчета, которые дают 80% полезной информации.
Покрытие — ищем страницы в статусе «не проиндексированы»
Откройте раздел «Покрытие» и отфильтруйте страницы, которые Google знает, но не берет в индекс. В 2026 году критических причин две.
Первая — «Обнаружена, но не проиндексирована: страница с перенаправлением». Это не всегда явный 301-редирект. Часто это цепочки: URL А ведет на Б, Б на В, а В на А. Поисковик зацикливается и бросает страницу.
Вторая — «Обнаружена, но не проиндексирована: дубликат без канонического адреса». Google находит страницу, видит, что она похожа на другую, но не понимает, какая главная. Решение — жесткая канонизация каждой страницы.
Карта сайта: включены ли туда важные страницы
XML-карта — это приглашение для поисковика. Даже если у вас идеальная структура, без карты сайта Google может находить новые страницы месяцами.
Проверьте, все ли значимые разделы перечислены в sitemap.xml. Типичная ошибка: в карту попадают только категории, а карточки товаров — нет. Или наоборот: карта забита тысячами дублей, а уникальные статьи про индексацию забыты.
Что делать: Убедитесь, что в sitemap.xml есть все URL, которые должны приносить трафик. Исключите служебные, технические, фасетные страницы.
Проверка рендеринга через инструмент «Проверка URL»
Самый недооцененный инструмент 2026 года. Вбейте любой URL коммерческой страницы, нажмите «Проверить URL», затем «Просмотреть проверенную страницу». Вы увидите два блока: HTML-код, который получил Google, и скриншот.
Сравните скриншот из Search Console с реальным видом сайта. Частая картина: шапка есть, подвал есть, середина страницы — пусто. Значит, контент в середине грузится после скролла или клика. Для Google этого взаимодействия не существует.
Анализ «невидимых» ошибок сервера
Код ответа 200, а пользователь видит «Что-то пошло не так». Современные сайты на JavaScript устроены так, что даже при сбое на сервере человек видит красивую картинку, а поисковик — пустую страницу. При этом формально сайт работает и отдает код 200.
В Search Console такие ошибки не отображаются. Их ловят специальными программами-роботами, которые просматривают сайт как живой человек — с включенными скриптами и стилями. Периодически прогоняйте важные разделы через такие инструменты.
HTTP-статусы, о которых забывают
Не только 404 и 5xx вредят индексации. Код 304 (Not Modified) говорит поисковику: «страница не изменилась, бери старую копию». Если вы обновили цену или добавили важный абзац, а сервер отдает 304 — Google может полгода показывать устаревшую информацию.
Код 410 (Gone) — жесткий сигнал «страницы больше нет и не будет». Это полезно для распроданных товаров, которые не вернутся. В отличие от 404, 410 очищает индекс быстрее.
Когда вы убедились, что Google видит страницы и берет их в индекс, наступает второй акт. Самое время ответить на вопрос: «Почему мой контент не используют для быстрых ответов и сниппетов?»
Право на сниппет: почему ваш контент не становится источником для нейросети
Иметь страницу в топ-3 по запросу — не значит получать переходы. В 2026 году Google все чаще оставляет пользователя на своей странице, показывая развернутый ответ. Ваша задача — заставить нейросеть процитировать именно вас.
Формат ответа: копируем структуру сниппета
Посмотрите на выдачу по вашему ключевому запросу. Что генерирует Google? Список из пяти пунктов? Таблицу сравнения? Короткое определение? Это идеальный формат вашего контента.
Нейросети обучаются на паттернах. Если в выдаче по запросу «как выбрать ноутбук» все сниппеты — списки из 5–7 пунктов, а вы написали эссе на 10 000 знаков без маркированных списков, нейросеть не сможет вытащить структуру. Она выберет конкурента, у которого четко: 1) процессор, 2) память, 3) экран и так далее.
Мы применили этот принцип в проекте для юридической компании Stepanov Group . Переформатировали статьи под формат «вопрос — ответ в первых 50 словах — маркированный список». За 8 месяцев SEO-работы трафик вырос в 7,5 раз.
Перевернутая пирамида для нейросетей
Забудьте про красивые вступления и общие фразы. Первое предложение под заголовком — готовый ответ на запрос.
Плохо: «Вопрос выбора автомобильного аккумулятора волнует многих водителей, особенно в зимний период…»
Хорошо: «Для зимы выбирайте аккумулятор с пусковым током не менее 500 Ач и емкостью на 10–15% выше рекомендованной заводом».
Нейросеть не оценит ваше литературное мастерство. Ей нужен факт, цифра, готовность к употреблению.
Уникальные данные: дайте нейросети то, чего нет у других
Google SGE оценивает новизну информации. Если ваш текст пересказывает первые пять статей из выдачи, ценность для искусственного интеллекта нулевая. Чтобы вас процитировали, нужны уникальные сведения.
Что это может быть:
- внутренняя статистика компании («по нашим данным, 73% клиентов возвращаются за повторной покупкой в течение месяца»);
- результаты опросов или исследований;
- конкретные кейсы с цифрами и сроками;
- фотографии процессов, чертежи, схемы (с корректным описанием в ALT-тегах).
Мы заметили: страницы с уникальными таблицами и графиками попадают в сниппеты в 4 раза чаще, чем обычные тексты.
Структурированные данные как язык искусственного интеллекта: аудит за 30 минут
Разметка Schema.org в 2026 году — не бонус, а допуск к аукциону. Без нее Google SGE просто не понимает, что перед ним — товар, статья, отзыв или инструкция.
Разметка отзывов и «исчезающие звездочки»
Вы все сделали правильно, но звездочки в выдаче пропали. Типичная история. Проверьте два момента.
Первый: совпадает ли рейтинг в разметке с тем, что видит пользователь? Если средняя оценка 4,2, а в JSON-LD стоит 5,0 — Google расценит это как обман и уберет сниппет.
Второй: доступность контента с отзывами. Если отзывы подгружаются по кнопке «Показать еще» или скрыты во вкладках, бот их не видит. Решение — выводить первые 3–5 отзывов статично, без необходимости клика.
FAQPage — самый быстрый путь в голосовой поиск
Каждый блок вопрос-ответ должен быть размечен как FAQPage. Это прямая дорога в голосовые ассистенты. Алиса, Маруся и Siri берут ответы именно из этой разметки.
Важное условие: вопросы и ответы должны быть видны сразу, без раскрытия. Если ответ скрыт под спойлером, нейросеть может его проигнорировать.
Product и Offer — обязательная норма для коммерции
Товар без разметки цены, валюты и наличия для Google SGE не существует. В 2026 году Google генерирует товарные блоки прямо в выдаче. Если у товара нет Schema.org/Product с заполненными полями, нейросеть не включит его в подборку.
Типичные ошибки:
- забывают указать валюту (priceCurrency);
- путают instock (есть на складе) и instoreonly (только в магазине);
- не ставят priceValidUntil для акционных цен.
Проверьте, чтобы цена передавалась в разметке статично, а не через JavaScript. Даже задержка в 1 секунду может стоить вам видимости.
После настройки разметки самое время вспомнить, что на сайт приходят не только люди и Googlebot, но и десятки других роботов. От того, кого вы пускаете, а кого блокируете, зависит, увидит ли искусственный интеллект ваш контент.
Robots.txt и управление ботами: кого пускать, а кого блокировать
В 2026 году на сайт приходят не только Googlebot, но и десятки других роботов. Одни нужны для поиска, другие — для сбора данных и обучения моделей. Разница критическая.
Кого обязательно пускаем:
- Googlebot — основной робот поиска. Без него сайта нет в Google.
- Googlebot-Image — для картинок.
- Googlebot-Video — для видео.
- Google-Extended — специальный бот для видимости в Gemini (Google AI). Рекомендуем разрешить.
- OAI-SearchBot — робот OpenAI для поиска ChatGPT. Если его заблокировать, ваш сайт не появится в ответах ChatGPT Search.
Кого можно смело блокировать:
- GPTBot — сбор данных для обучения ChatGPT. На видимость в поиске не влияет.
- CCBot — робот Common Crawl (открытая база для обучения).
- ClaudeBot — робот Anthropic.
- Bytespider — робот ByteDance (TikTok).
Проверьте файл robots.txt на предмет случайных блокировок. Мы находили случаи, когда директивой Disallow: / закрывали вообще все, оставляя доступ только главной странице.
Контент-аудит на пригодность для нейросетей: убираем «воду» и добавляем факты
Искусственный интеллект не понимает «красивый текст». Он понимает «плотный текст». Плотность здесь — количество смысловых единиц на 1000 знаков.
Проверка на смысловые единицы (сущности)
Сущности — это имена, даты, географические названия, бренды, термины. Текст без сущностей для нейросети — просто набор слов. Ей не за что зацепиться.
Сравните два фрагмента:
«Наша компания работает много лет и помогает бизнесу расти».
«Компания SEOJazz с 2017 года привлекла более 15 000 заявок ежемесячно для клиентов из Москвы, Санкт-Петербурга и регионов».
Во втором случае нейросеть извлекает: дата (2017), цифра (15 000), география (Москва, Санкт-Петербург), отрасль (бизнес, заявки). Шансы на цитирование вырастают в разы.
Таблицы и списки против сплошного текста
Google SGE обожает таблицы. Сравнение характеристик, тарифов, моделей в табличном виде — идеальный формат для парсинга. Нейросеть легко копирует таблицу целиком в свой ответ, со ссылкой на источник.
Переформатируйте все, что можно сравнить, в таблицы. Сплошной текст длиннее 1500 знаков без разбивки автоматически снижает шансы на сниппет.
Внешние сигналы: почему одного сайта недостаточно для цитирования
Нейросеть проверяет ваши слова по другим источникам. Это встроенный механизм доверия. Если вы утверждаете, что «вы — лидер рынка», а больше никто в интернете вас так не называет, Google SGE проигнорирует страницу.
Цифровой PR и работа с упоминаниями становятся фактором ранжирования. Не просто ссылки, а контекстные упоминания бренда на авторитетных площадках. Чем больше независимых источников подтверждают вашу экспертизу, тем выше вероятность попасть в сниппет.
Авторство статей — обязательный элемент. У каждой публикации должно быть указано имя реального человека с краткой биографией. Google предпочитает контент, созданный людьми, а не сгенерированный безлико. Автор с портретом и описанием опыта — сильный сигнал качества.
Аналитика: как отслеживать видимость в поиске с искусственным интеллектом
Старые метрики врут. Вы смотрите в Search Console: позиции те же, трафик упал. Вы не сошли с ума, это новый поиск.
Доля поиска (Share of Search)
Единственная метрика, коррелирующая с реальной долей рынка. Как считать без дорогих инструментов:
- Выберите 10–20 ключевых запросов в вашей нише.
- Определите 5 прямых конкурентов.
- Раз в неделю вручную или через бесплатные парсеры собирайте данные: сколько раз каждый бренд появляется в топ-10.
- Сведите в Excel: сумма упоминаний вашего бренда / сумма упоминаний всех брендов × 100%.
Динамика доли поиска точнее всего показывает здоровье бренда в эпоху искусственного интеллекта. Если доля растет — бизнес в порядке, даже при падении абсолютного трафика.
Упоминания в обзорах искусственного интеллекта
Это новая валюта. Пока нет стандартных инструментов для массового мониторинга. Берете 20–30 ключевых запросов, смотрите выдачу, фиксируете, какие источники цитирует Google SGE. Через месяц повторяете замер.
Переходы из блоков атрибуции
Google начал явно указывать источники в AI-обзорах. Часто это карусель ссылок или блок «Источники информации». Сегментируйте трафик по этим переходам. Обычно они приходят как прямые заходы или органические с UTM-метками, содержащими sge, ai, featured.
Часто задаваемые вопросы об индексации и сниппетах
Нужно ли переделывать весь старый контент под новые требования?
Не обязательно весь. Достаточно переписать первые абзацы на коммерческих и информационных страницах, которые приносят основной трафик, и добавить разметку FAQPage.
Как быстро Google SGE начнет цитировать исправленную страницу?
Обычно от 2 до 6 недель. Нейросеть обновляет свои модели не в реальном времени, а циклами. Ускорить процесс можно через ручную переобход в Search Console.
Влияет ли скорость загрузки на право на сниппет?
Косвенно — да. Если страница грузится дольше 3 секунд, Googlebot может не дождаться рендеринга контента и разметки. Core Web Vitals остаются фактором ранжирования.
Что важнее — структурированные данные или уникальный контент?
Это сообщающиеся сосуды. Разметка помогает понять страницу, контент — дает ответ. Без ответа разметка бесполезна, без разметки ответ могут не заметить.
Заключение
Вы дочитали до конца, и теперь у вас есть полная картина. Проверка индексации и права на сниппеты в 2026 году — это не разовый аудит, а смена подхода. Мы в SEOJazz убедились на своих кейсах: чтобы доминировать в поиске, недостаточно нарастить ссылочную массу. Нужно заставить нейросеть доверять вам.
Краткий план действий на 60 минут:
- Проверьте рендеринг трех ключевых страниц через Search Console.
- Отловите фасетные дубли и закройте их в robots.txt.
- Убедитесь, что структурированные данные видны в исходном коде.
- Посмотрите статус «Обнаружена, не проиндексирована» — разберите причины.
- Проверьте robots.txt на блокировку OAI-SearchBot и Google-Extended.
- Перепишите вступление на главных страницах под формат «прямой ответ».
- Внедрите разметку FAQPage для раздела «Вопрос-ответ».