Осенью 2025 года состоялся публичный запуск софта: SEO Semantic Lab.
И мы решили узнать: как он работает и в чем его уникальность.
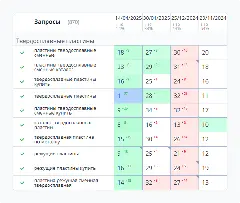
SEO Semantic Lab - SEO-софт для стратегии и кластеризации поисковых запросов.

1) С какой проблемой вы лично столкнулись, что смотивировало написать собственную программу SEO Semantic Lab? Какую задачу вы перед собой ставили?
Изначально у меня был собственный кластеризатор, который по техническим ограничениям (память/ресурсы) стабильно работал примерно до 8 тысяч запросов. Но в реальной работе ядра часто бывают 100–200 тысяч запросов, и разбивать их на десятки итераций по 8 тысяч — это долго, дорого и, главное, всё равно приводит к ошибкам: в первую очередь к каннибализации и “разъезжающейся” структуре.
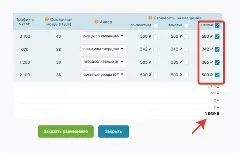
Я написал Python-скрипт, который позволил кластеризовать большие ядра корректно и воспроизводимо. Дальше я перенёс в программу накопленную Excel-логику “скоринга” и приоритизации (которую раньше делал макросами), и так появилась идея SEO Semantic Lab: автоматизировать путь от семантики к конечному результату — структуре посадочных, понятной стратегии и прикладным ТЗ на контент и внедрения, чтобы это влияло не только на позиции, но и на лиды/продажи.В какой-то момент я понял, что это надо упаковать в продукт: сделать инструмент, который закрывает полный цикл - от семантики до готовых внедряемых ТЗ, а не просто “раскидать фразы по группам”.
Задача была максимально бизнесовая: чтобы после работы с ядром у вас на выходе было не “красиво сгруппировано”, а понятно:
- какие страницы создавать и в каком порядке;
- где есть быстрые победы (низкая конкуренция/высокий спрос);
- где у тебя дырка в структуре относительно топа;
- и что именно на странице должно быть, чтобы она реально начала приносить трафик и лиды.
2) В чём принципиальное отличие подхода Semantic Lab к построению семантического ядра от традиционных методов “по частотности”?
Традиционно ядро часто строят так: собрали фразы, отсортировали по частотности, сгруппировали по словам, назвали кластер маркером — и дальше начинается “магия на глаз”: какую страницу делать, какой тип контента, как избежать пересечений, что именно писать.
В SEO Semantic Lab логика другая: мы не начинаем с частотности - мы начинаем с выдачи. На входе - факт: запрос → позиция → URL, и дальше алгоритм оценивает, какие URL реально “несут” интент, какие страницы сильнее, как правильно привязать запросы к посадочным так, чтобы не плодить мелкие кластеры, которые будут каннибализировать друг друга.
А уже потом мы накладываем слои: частотность, бюджеты, конкурентов, прогнозы, доли Яндекс/Google, конверсии/роботность (если выгружены из Метрики/консолей). И на выходе получается не просто “семантика”, а план работ: какие посадочные нужны, как выглядят эталоны, где вы отстаёте и что нужно внедрить.
Для владельца бизнеса это про понятный ответ на вопрос: “Что конкретно делать на сайте, чтобы забрать спрос?”
Для SEO - это про системность: не гадать, а повторять успешные паттерны выдачи.
3) Как кластеризация учитывает семантическую близость и контекст? Насколько адаптирована под русский поиск?
Мой подход - это интентная кластеризация по фактическим данным выдачи, а не “семантика слово-к-слову”. Я не пытаюсь соединять запросы на основе косинусных близостей или внешних словарей “смыслов”. Вместо этого используется то, что уже “решил” поисковик: если по запросам ранжируются схожие URL/домены, значит интент близок, и эти запросы логично продвигать вместе.
Алгоритму по сути не важен язык - важны данные: запрос, позиция (обычно 1–10) и URL. Поэтому метод воспроизводимо работает и в русскоязычных, и в других нишах. А к особенностям русского поиска он адаптирован за счёт того, что опирается именно на русскоязычный SERP (Яндекс/Google), где морфология и формулировки особенно сильно влияют на интент и тип выдачи.
Плюс поверх кластеризации у меня есть слой контекста: в текстовом анализе смотрится окружение ключевых слов (что стоит рядом с запросами у лидеров). Это даёт правильные “смысловые добавки” для текста и заголовков - без переспама и без попыток угадать, “как надо”.
4) Учитывает ли программа изменения в алгоритмах (BERT/MUM/YandexGPT) при пересчёте релевантности и структуры?
Я честно считаю, что самый надёжный способ “учитывать апдейты” - это не читать новости и не гадать, что именно поменяли, а смотреть на то, что реально ранжируется сейчас.
Если поисковики меняют понимание интента или качества - меняется выдача: состав лидеров, типы страниц, структура контента в топе. В SEO Semantic Lab вы обновляете входные данные (SERP/позиции/конкуренты) — и система автоматически перестраивает кластеры и рекомендации под новую реальность.
Дальше включается “технарская” часть:
- прямые вхождения запросов по зонам (title/h1–h6/текст/списки/ссылки/nav/alt),
- TF-IDF, BM25,
- n-граммы (включая 4–5-граммы),
- контекстное окно вокруг ключей у лидеров,
- микроразметка конкурентов как часть структурирования для ИИ-поиска.
То есть программа помогает не “переиграть алгоритм”, а собрать страницу, максимально похожую на то, что уже доказывает эффективность в топе, но при этом закрывающую ваши пробелы.
5) Есть ли автоматическое выявление “семантических дыр” относительно конкурентов? Как это превращается в рекомендации?
Да. На уровне стратегии я вижу кластеры, где конкуренты присутствуют в топ-10, а моего сайта там нет — это прямой сигнал “у нас нет посадочной / нет релевантности”. Также видно, где средняя позиция далеко за топ-50/100 — значит страница либо отсутствует, либо не соответствует интенту топа.
Дальше это превращается в конкретику: какой кластер требует новую страницу, какой — доработку, где каннибализация (несколько URL сайта ранжируются по одному кластеру), и как выстроить структуру.
А на уровне текстового анализа я получаю “семантические дыры” по контенту: каких терминов/тем/формулировок не хватает, и в каких зонах у лидеров они встречаются.
Это превращается в понятное ТЗ: что добавить в заголовки, что — в списки/FAQ/таблицы, что — в анкоры и навигацию.
6) Как обрабатывается user intent: NLP, поведенческие метрики или другие сигналы? Насколько точна дифференциация коммерции и инфо?
В большинстве проектов самая дорогая ошибка — написать “идеальный текст” не под тот интент. Поэтому я ставлю интент в центр.
У меня intent определяется двумя слоями:
1) Выдача и лидеры
Если в топе статьи — значит информационный интент. Если в топе категории/услуги/карточки — значит коммерческий. Если смешанная выдача — значит нужно гибридное решение: структура + контент, которые закрывают обе потребности.
2) Контент и признаки лидеров
Я анализирую, какие слова и сущности реально используются у лидеров рядом с ключами, какие блоки встречаются чаще. “Цена/стоимость”, “отзывы”, “программа”, “условия”, “сроки”, “гарантии”, “прайс-лист”, “калькулятор” и т.д. — это не просто слова, это маркеры ожиданий пользователя.
Поведение (визиты/роботность/конверсии) подключается как усилитель, если у вас есть данные из Метрики/консолей. Тогда можно не просто “делать как у топа”, а приоритизировать по качеству трафика и потенциальным лидам.
7) Какие кейсы подтверждают рост конверсий и снижение CAC?
SEO Semantic Lab как продукт действительно свежий (публичный запуск — осень 2025), поэтому по части “CAC в цифрах” я аккуратен: для этого нужны полноценные кейсы с аналитикой и разрешением клиента на публикацию.
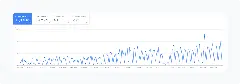
Но сам подход, на котором построен инструмент, как раз про бизнес-результат: при подключении данных из Метрики/консолей я агрегирую показатели по кластерам — включая конверсии/цели и долю роботов — и можно выбирать приоритеты не по частотности, а по ожидаемой ценности. Ещё до выхода продукта у меня были проекты, где я оказывал услугу “скоринг/стратегия по семантике” на этой логике: внедрение недостающих посадочных и точечная доработка страниц (включая метатеги и структуру) давали рост видимости и трафика, а в ряде ниш — рост заявок.
Как публичный пример я обычно привожу собственный сайт/блог: он растёт без накруток поведенческих и без “серых” методов — за счёт правильной структуры, контента и соответствия интенту топа. По клиентским кейсам я готов дать конкретику после согласования: ниша, период, что внедряли, как изменились лиды/CR и какая динамика по органике.
В завершение: “чтобы SEO-шник захотел прямо сейчас”
Если упростить, SEO Semantic Lab отвечает на три вопроса, которые в реальных проектах стоят денег:
- Какие посадочные страницы нам реально нужны, чтобы охватить спрос?
- Какие из них дадут быстрый результат и какой приоритет по бизнес-эффекту?
- Что именно должно быть на странице (структура, зоны, термины, микроразметка), чтобы она вошла в топ?
И это всё - не на уровне “ощущений”, а на уровне данных выдачи и контента лидеров.